For the last thirty years, SaaS products have quietly relied on a workaround: a human at a computer, gluing together context the systems wouldn't share with each other. Not because the integration was technically hard. Because the products didn't want to share. Hoarding context is how SaaS wins, sharing with a neighbor lowers switching cost, which is easy to deprioritize.
At every business there's spreadsheets that are load bearing for the business. These are so prevalent there's a term for them: End-User Developed Applications (EUDAs). Most exist to fill contextual gaps, system A holds some context, system B holds some other context, and a spreadsheet and humans glue it together. If you're lucky, it's somewhere shared and backed up rather than just someone's desktop. If you're unlucky, there's not even a spreadsheet, it's just in someone's head.
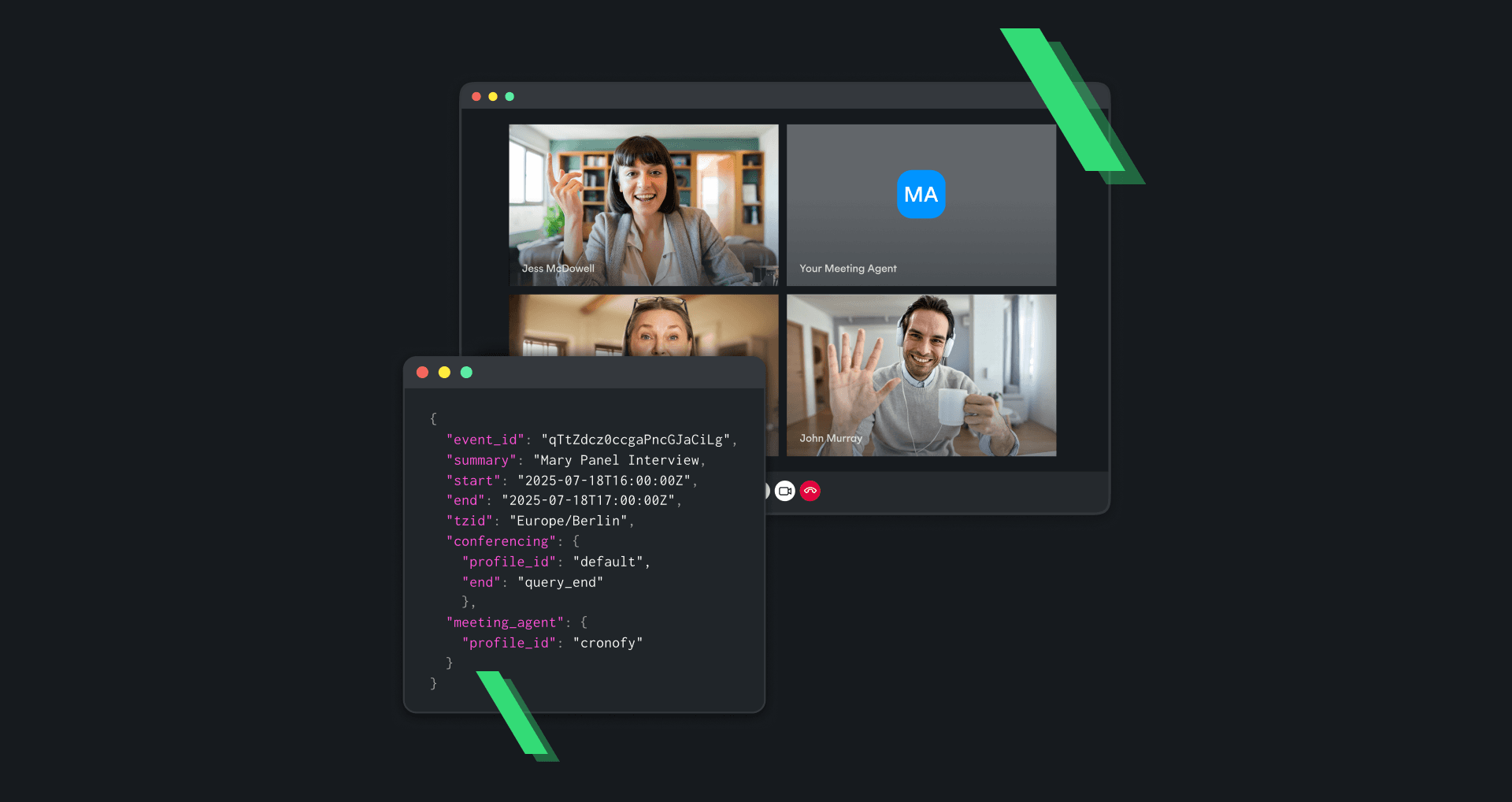
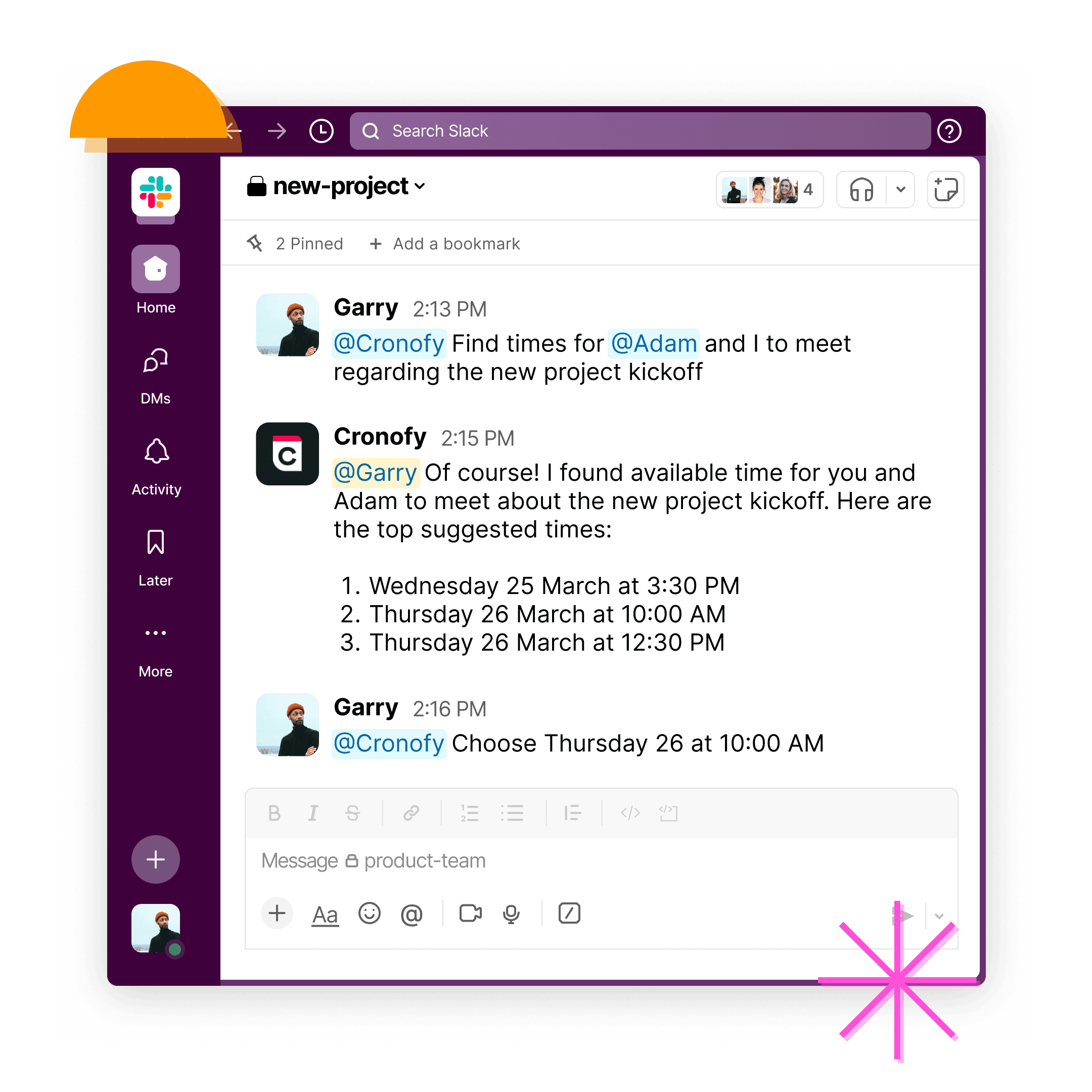
A common version of this in scheduling is something most people will recognize - either because they did it, or because they watched someone else do it. A recruiter opens the Applicant Tracking System (ATS) to see where a candidate is in the pipeline, switches to their calendar to find a slot, mentally cross-references the hiring manager's preferences, checks the candidate's availability over email, books the room, updates the ATS, sends the invite. Somewhere in the middle they remember that this particular interviewer doesn't take meetings on Fridays unless the candidate is strong enough to make it worth their while.
The recruiter wasn't routing information. They were combining context from several systems - calendars, the ATS, the CRM, whatever else mattered - and applying rules that might be in a spreadsheet. The systems weren't connected so the human was the glue.
Why the integration never happened
It isn't always a conscious decision that data is inaccessible. Where context isn't actively hoarded, programmatic access often just isn't prioritized. The need hasn't been high enough. Google has had an open feature request for an API to expose working hours since 2018, it just isn't a priority for them to build and support that over other features.
Where humans are the glue, building software to do the work of those people was prohibitively expensive, if it was possible at all. The result was a stack of well-designed silos held together by people doing coordination work by hand.
What agents change
Rote automation has been possible for decades. Roughly speaking, if a workflow could be fully automated at reasonable cost, it already has been. Agents are interesting because they can operate in the fuzzy area where previously only humans could.
Agents can also work around the API problem by driving the human interface when necessary, alongside the APIs available. It's slower than using an API, but it makes the impossible possible, and that's often enough.
Plenty of back-office systems were built in-house and never needed an API because there was no demand for one. Others were built thirty years ago when APIs weren't really a thing. These systems are often critical to how the business functions, and there's real inertia behind them. Agents are the first thing capable of making them part of modern workflows.
Agents aren't capable of taking on all of this work, some parts still need human judgment, or a human touch. But through a combination of being able to combine siloed contexts and a level of pattern recognition, they can take on a lot of low-value, rote work. That leaves the interesting parts of work for the humans in the loop.
Speed is the whole game
A human coordinator takes minutes, hours, or days. An agent can do the same work in seconds.
We've seen countless examples of how this plays out. For example, Wise cut interview scheduling from 6 days to 90 minutes using Cronofy. Most of that win came from temporal infrastructure and automation rather than agents, but the principle generalizes: collapsing coordination time is where the value is, and agents can address fuzzier cases that pure automation cannot.
Scheduling is often the major bottleneck in hiring. The actual interviews might take a day of human time spread across a process, but it can take weeks for those interviews to actually happen. If you can complete the process and make an offer in the time it takes a competitor to arrange their screening call, you improve your odds of hiring the best candidates and filling the position sooner.
There are echoes of lean manufacturing here. The "work in progress" (WIP) of knowledge work are the workflows in progress at any point in time. The bottlenecks in a workflow are the decision points. If there's a fork in the road someone, or something, needs to decide which path to take. Agents can take more of those decisions away from human minds, but that will move them on to a step where a human is necessary. Be it a conversation with a customer is necessary to drive a decision, or a sign off for a contract, at some point in a high-value workflow a human is needed.
Humans have always been the bottleneck in workflows, but it will be even more apparent when the decisions they are involved in reduce, but become more important.
Making the low-value calls and understanding relevant context is where agents remove the busywork of any given workflow. They need to pull on human time for workflows to progress, especially if it requires several of them to move forward.
Weeks to minutes, hours to seconds. That order of magnitude is where the transformation lives.
Calendar Tetris
One human in the loop is annoying but survivable. The problem doesn't degrade linearly as you add more people - it follows a power curve. Calendar Tetris is a term we've heard used for it, with one important difference: the rows don't disappear, you just never seem to get the shape you need.
Once enough people are involved, there's no time when everyone is truly free, and you end up going around in circles asking about exceptions with a single coordinator at the center. Agents can streamline this by holding several of those conversations in parallel without losing sight of the bigger picture. Agents can scale horizontally on-demand in a way that a human workforce just cannot.
Decision points like "when can we meet to get to a decision on this" takes five minutes rather than five hours. The workflow presses on a day sooner.
What temporal infrastructure actually contains
Real-time availability is the obvious part. The less obvious parts are what make it infrastructure rather than a feature.
Declared future intent matters. So do pre-approved decisions the agent can enact on without escalating - what we think of as pre-approved availability. An interviewer earmarks Tuesday and Thursday afternoons specifically for interviews, separate from their general working hours, and they can be booked within that window without asking. For some, more control is needed in terms of time demanded, an individual contributor involved in hiring can declare a ceiling of one interview a day and three a week.
These contextual rules are what move you from "good old scheduling" to the temporal grid. It's easy to know when someone is free according to their calendar, but there's a lot more nuance into knowing when someone is available.
The rules are attached primarily to the person's identity but also to context from the system of record. If it's a high-value client, a strong candidate, or an important role, the rule may bend. The temporal grid is where these rules live because the grid is what lets us expand from "weekday afternoons are for interviews" to "are Tuesday mornings good for X like they are for Y?"
The source of these rules doesn't really matter. The person might declare it themselves. A coordinator or manager might set it up on their behalf to satisfy a requirement without the person having a say. An agent might infer it from behavior and propose it back for confirmation. What matters is that the rule is surfaced, stored, and distributed appropriately.
The access model matters as much as the rules
Most people building agent infrastructure assume the hard part is the rules. At least as hard, if harder, it's deciding who gets to see them and at what fidelity.
A sales agent might see that a particular interviewer is unavailable at a given time without seeing why. A candidate-side agent sees even less. They don't know who is available, just that the time itself is available to them. We do this today: candidates use single-use scheduling links that show only the times open to them. The details of the panel, who's involved, why a slot is blocked, are completely hidden.
Permissions filters have to exist alongside the rules, and quite often the existence of those filters is a prerequisite for anyone being willing to share their availability in the first place.
This is also why temporal infrastructure can't sit inside any single SaaS product. No single product can see across the organization, and no single product can be trusted to abide by rules that aren't theirs to hold.
What rules engines can't do
Our rules engine today handles firm availability: working hours, buffer times, constraints; layered on top of the live availability from people's calendars. It's powerful and meets the vast majority of needs, but it has a ceiling.
"I could move an internal meeting to accommodate that external one" is something a human will tell you immediately, but is genuinely hard to encode as a rule. The decision usually comes down to an equation in someone's head full of "it depends" and "unless", which they probably couldn't fully enumerate even if asked. It's all about the specific context at hand.
This is what agents are for - not a better rules engine, but a different kind of capability entirely.
Layers of agents
The future isn't about one single agent. It is many specialists working in harmony.
A scheduling agent may defer to a rule-based agent in the first instance, then deploy more heuristic-based agents depending on the outcome. Those in turn may pull on the coordinating agent for more context to inform the scheduling question, ie. "is this a high value deal?", to unlock another layer of permissions and rules.
Eventually, if needed, it escalates to a human:
Hi Ada, we're looking to arrange a meeting with MegaCorp, can I move your 1:1 with Alan on Friday for this? Everyone else is free at that time. I'll let Alan know the context if you agree.
Scope and context expands only as needed. This limiting risk by not oversharing and improves efficiency by using the simplest solution possible.
A scheduling scalpel most of the time, but able to call on a human with an axe when needed.
What this opens up
The biggest opportunity isn't the meetings that agents will book that humans would have booked anyway. It's the meetings that don't happen today because the latency makes them pointless.
"I think we're good to go, but we need a meeting with the exec team before we move." That meeting might take four weeks to land, and the entire initiative waits behind it. The coordination cost is higher than the perceived urgency, so the meeting either drifts or never happens, and the project ages while it does. Collapse the coordination cost and the math changes. Meetings that wouldn't survive a four-week scheduling delay become viable because they can happen tomorrow.
As we automate what is now possible, new bottlenecks and new possibilities will reveal themselves, either to humans or to agents. Most of them we can't imagine today.
Systems always benefited from temporal context but humans absorbed the cost. A waiting agent is no faster than a human.